最近对服务器进行了一次性能优化,这里记录一下要点以供备忘。
Go Profile
golang 官方提供了一个称为 pprof 的性能调优工具。我们可以利用该工具来进行诊断。pprof 的原理是每秒钟暂停100次,然后对当前正在运行的 goroutine 堆栈进行采样并记录次数。
pprof 开启
对于服务器,一般通过 http 方式来启用 pprof,例如
1 | import _ "net/http/pprof" |
pprof 诊断热点函数
1 | go tool pprof bin/sessionsvr http://your-ip:port/debug/pprof/profile?seconds=30 |
30秒后,数据采集完成,top20 可以列出 CPU 占用最高的20项,结果如下
1 | (pprof) top20 |
其中前两列 flat 表示该函数调用的时间和百分比,后两列 cum 表示该函数处于堆栈中的时间和百分比,包含正在被调用或者等待其他子函数返回的情况。 sum 表示前面 N 行到当前行函数累计的时间百分比。
从上面的结果可以知道 cum% 为 59.57% 的 moveSight 函数长时间处于栈列表中,是正在运行或者等待该函数里面其他函数调用返回。而其很可能主要等待前面几个 map 的操作完成。
运行下面的命令
1 | (pprof) top mapassign1 |
用浏览器打开 生成的结果 cpu.svg 可以看到
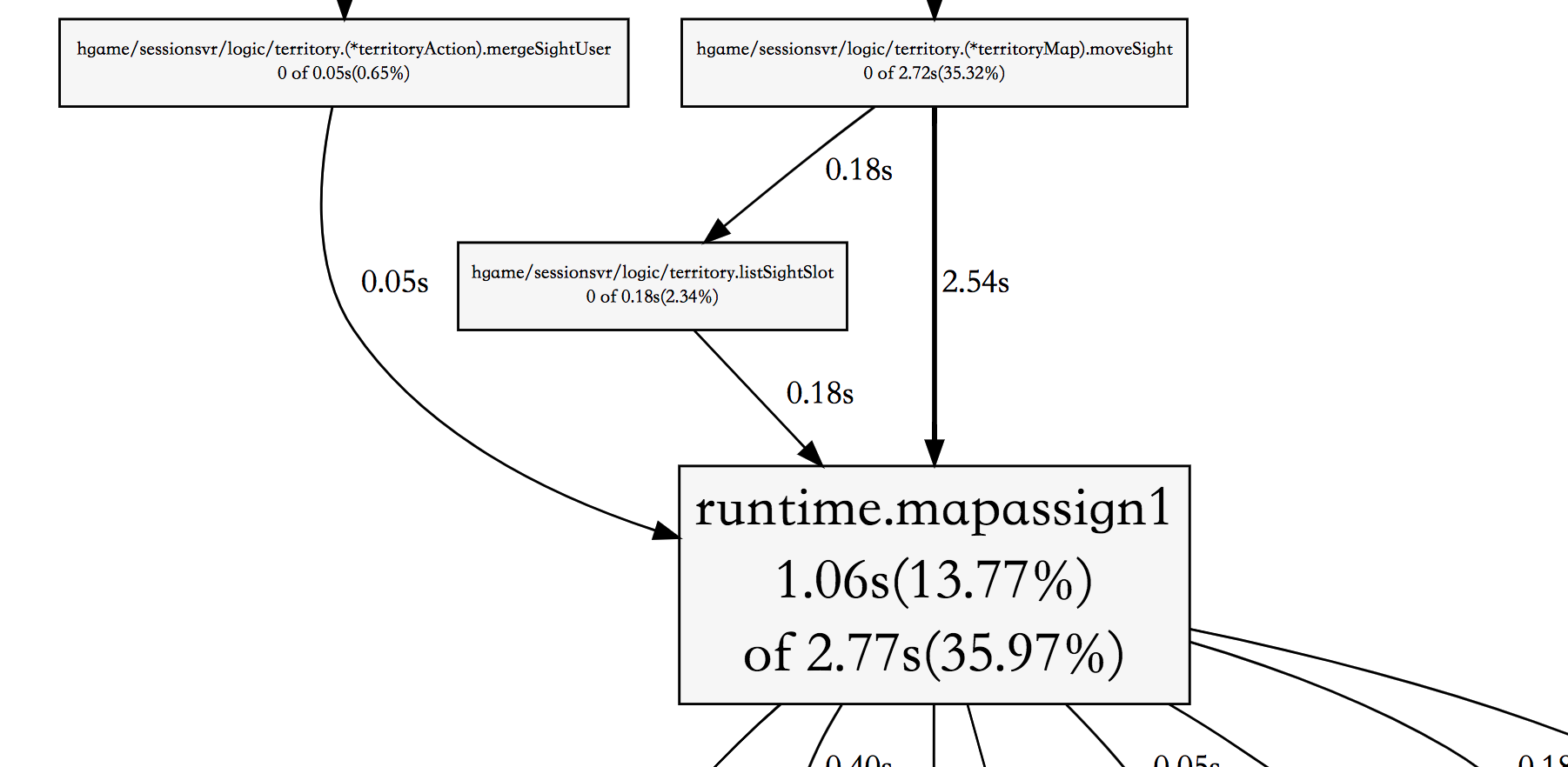
从图中可以证实,确实是 moveSight 导致的 map 操作占用 CPU 时间较多。
利用 list 命令查看具体是那一行
1 | (pprof) list moveSight |
找到具体数据结构后,就可以有针对性的修改。一般来说 map 的优化主要是 key 要使用比较简单的类型,这样计算 hash 的时候也比较快。通常来说 int 类型 key 比 string 类型的 key 要快。此外由于 map 的内存增长是指数级的,新插入的时候如果发现空间不足,需要重新分配空间 hashGrow 和进行内存 typedmemmove,很耗性能,所以如果能预估 map 的大小,最好一开始就分配足够大的空间,以空间换时间。
机器人策略
Lua Profile
- 数据库数据的分批拉取、存储。Mysql 一次 update 多条记录会比多次 update 快。(有网络开销,获取锁开销等)
- 配置数据的加载,预处理。
- map 或者 slice 预分配空间大小,减少频繁扩容及数据拷贝代价。
- 注意共享资源锁的粒度。
- 数据更新量。大且频繁的数据使用版本号做增量通知。
- 算法优化:KDtree 查找距离最近,KNN 算法;模糊查找算法。
- 广播裁剪
- 包大小优化,序列化方法,压缩
- 登录模块,预分配 user 池
- 增加 metrics 统计项,及早发现问题
- snap 快照对比,找出 lua 内存泄露
- lua 有性能问题的地方改用 c 或者 go 实现(加解密、time、socket、json 等序列化、随机数发生器、位操作)
- gettimeofday
- 避免密集操作,如避免定点发放物品,分批发放
- 利用 goroutine 多核并行执行
- 空间换时间
- 消峰:均摊思想。例如哈希表的扩容时候,不是一次做完数据迁移。
- 用 SSD 硬盘。
- 数据库分表分库,读写分离
算法调优
代码调优
- 尽量用整形取代字符串(例如用整形 flags 来表示多个状态,利用位操作来查询设置状态;数据库用整形做 key)
- 单线程中,不要用带锁相关的数据结构,很多 stl 的线程安全的容器或者智能指针 AutoPtr 都是加锁的,很耗性能;多线程环境下,尽量用无锁编程,乐观锁,读写锁等来替代互斥锁、悲观锁;最后,尽量用单线程
- 池化技术:内存池、对象池、连接池、线程池
- 缓存技术:LRU 缓存
- 将同步操作转换为异步操作,提高 throughout
网络调优
- 及时关闭空闲连接,避免资源耗尽。客户端服务器心跳 keepalive 机制。
- TIMEWAIT 状态的处理。
- TCP buff 的选择。理论上的RWIN应该设置成:吞吐量 * 回路时间。Sender端的buffer应该和RWIN有一样的大小,因为Sender端发送完数据后要等Receiver端确认,如果网络延时很大,buffer过小了,确认的次数就会多,于是性能就不高,对网络的利用率也就不高了。也就是说,对于延迟大的网络,我们需要大的buffer,这样可以少一点ack,多一些数据,对于响应快一点的网络,可以少一些buffer。因为,如果有丢包(没有收到ack),buffer过大可能会有问题,因为这会让TCP重传所有的数据,反而影响网络性能。
- 对于一个UDP的包,我们要尽量地让他大到MTU的最大尺寸再往网络上传,这样可以最大化带宽利用率。对于这个MTU,以太网是1500字节,光纤是4352字节,802.11无线网是7981。
- Epoll 的使用。
- DNS lookup。gethostbyaddr/gethostbyname 这个函数可能会相当的费时,因为其要到网络上去找域名,因为DNS的递归查询,会导致严重超时,而又不能通过设置什么参数来设置time out,对此你可以通过配置hosts文件来加快速度,或是自己在内存中管理对应表,在程序启动时查好,而不要在运行时每次都查。
数据库调优
- 选对引擎
- 索引
- 数据类型选择
- 分表分库
- 读写分离
实现层优化:vtune 等工具查找热点,针对性优化。
实现层优化:空间换时间,为高频不善变计算建立缓存。
- 业务层优化:柔性可用,设立资源消耗配额(定时重置),每次请求消费一个配额,控制总体。
- 业务层优化:有损服务,对业务需求进行必要裁剪。
参考资料