C/C++ 是高级编译型语言,执行的时候需要将容易阅读的源码编译成机器可以识别的机器指令,交由 CPU 执行。这篇文章我们来研究一下编译是怎样一个过程。
绝大多数编译器并不是一个单一的庞大程序,它通常由六七个稍小的程序组成,这些程序由一个叫做『编译器驱动器』(compiler driver) 的控制程序来调度。整个编译过程大致可以分为四个主要阶段:
- 预处理
- 编译
- 汇编
- 链接
我们以一个简单的 c 程序来举例,c 代码如下
1 |
|
在 centos 环境利用 gcc 进行编译,添加选项 -save-temps 我们可以获取编译过程每个阶段产生的临时文件
1 | $ gcc -Wall -save-temps -DDEBUG filename.c -o filename |
可以看到分别生成了以下文件

其中
filename.c 源码文件
filename.i 预编译后文件
filename.s 汇编文件
filename.o 编译目标文件
filename 链接后的可执行文件
下面我们分别看看每个阶段具体在进行哪些操作。
预处理
预处理阶段,编译器驱动调动预处理器处理 预处理指令 ,所谓预处理指令是指以 # 开头的指令,主要有注释、宏、头文件包含、条件编译等,因此这个阶段包括以下几个操作
- 去除注释
- 展开宏定义
- 展开头文件包含
- 条件编译
#ifdef、#ifndef处理 - error 抛出错误信息
我们打开预处理后的 filename.i 文件可以看到:注释被去除了,参数宏 add(a, b) 也被 (a + b) 替换,包含的头文件 <stdio.h> 中的内容被拷贝到源文件 filename.c 中;此外编译时候有没有指定 -DDEBUG 得到的结果 (是否有myfunc) 也不一样。
其他的预处理指令还包括 pragma、 line 等,这里就不详细说明了
编译
编译阶段,主要将扩展的源码文件如filename.i 编译成汇编文件filename.s。其中又分为三个主要步骤:
Lexical Analysis / tokenization 词法分析。
主要就是将输入的源码文件从左到右逐个字符(character)的分析,划分成不同的 token:symbols, numbers, identifiers, strings, operators 等。下面看个例子
1
2
3
4
5
6
7
8
9
10
11int main() {
int a;
int b;
a = b = 4;
return a - b;
}
//经过词法分析,会产生以下 token
Scanner production:
[Keyword(Int), Id("main"), Symbol(LParen), Symbol(RParen), Symbol(LBrace), Keyword(Int), Id("a"), Symbol(Semicolon), Keyword(Int), Id("b"), Symbol(Semicolon), Id("a"), Operator(Assignment), Id("b"),
Operator(Assignment), Integer(4), Symbol(Semicolon), Keyword(Return), Id("a"), Operator(Minus), Id("b"), Symbol(Semicolon), Symbol(RBrace)]Parsing 语法解析。
该过程是将上面词法分析产生的 tokens 进行匹配,看是否符合特定的模式:如函数调用、变量赋值、数学运算、表达式求值等等。最终,语法分析会产生一种称为 AST (abstract syntax tree) 的语法树结构。
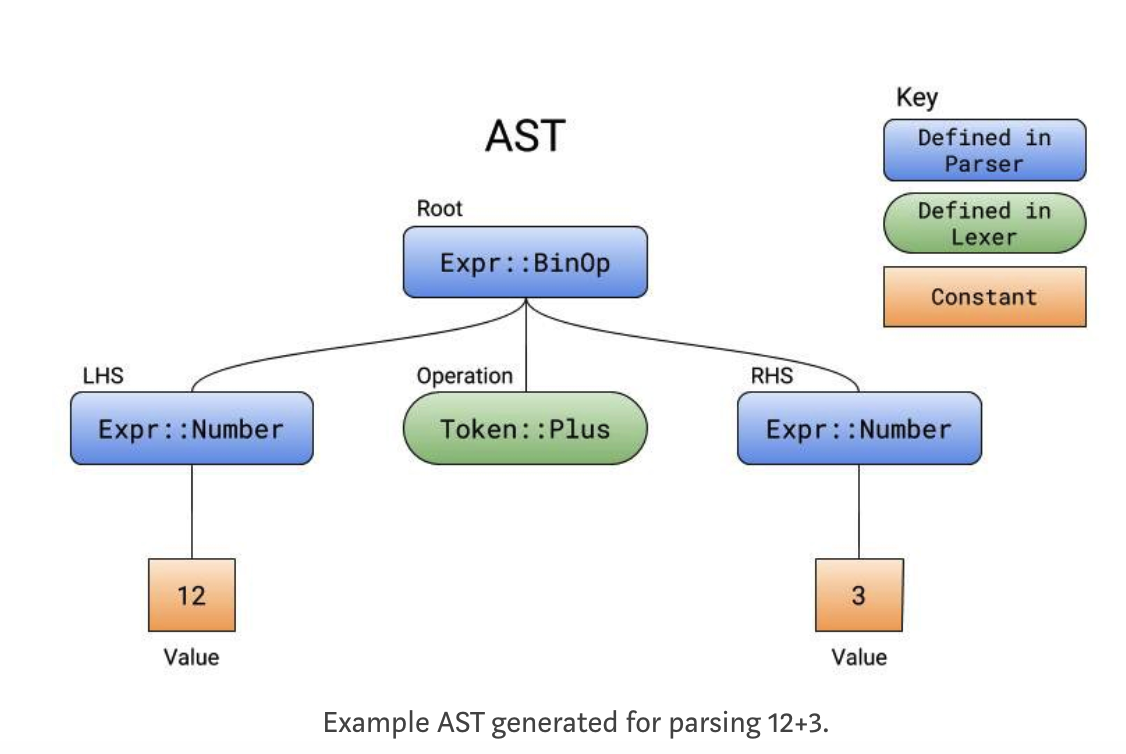
上面就是
12 + 3对应的AST结构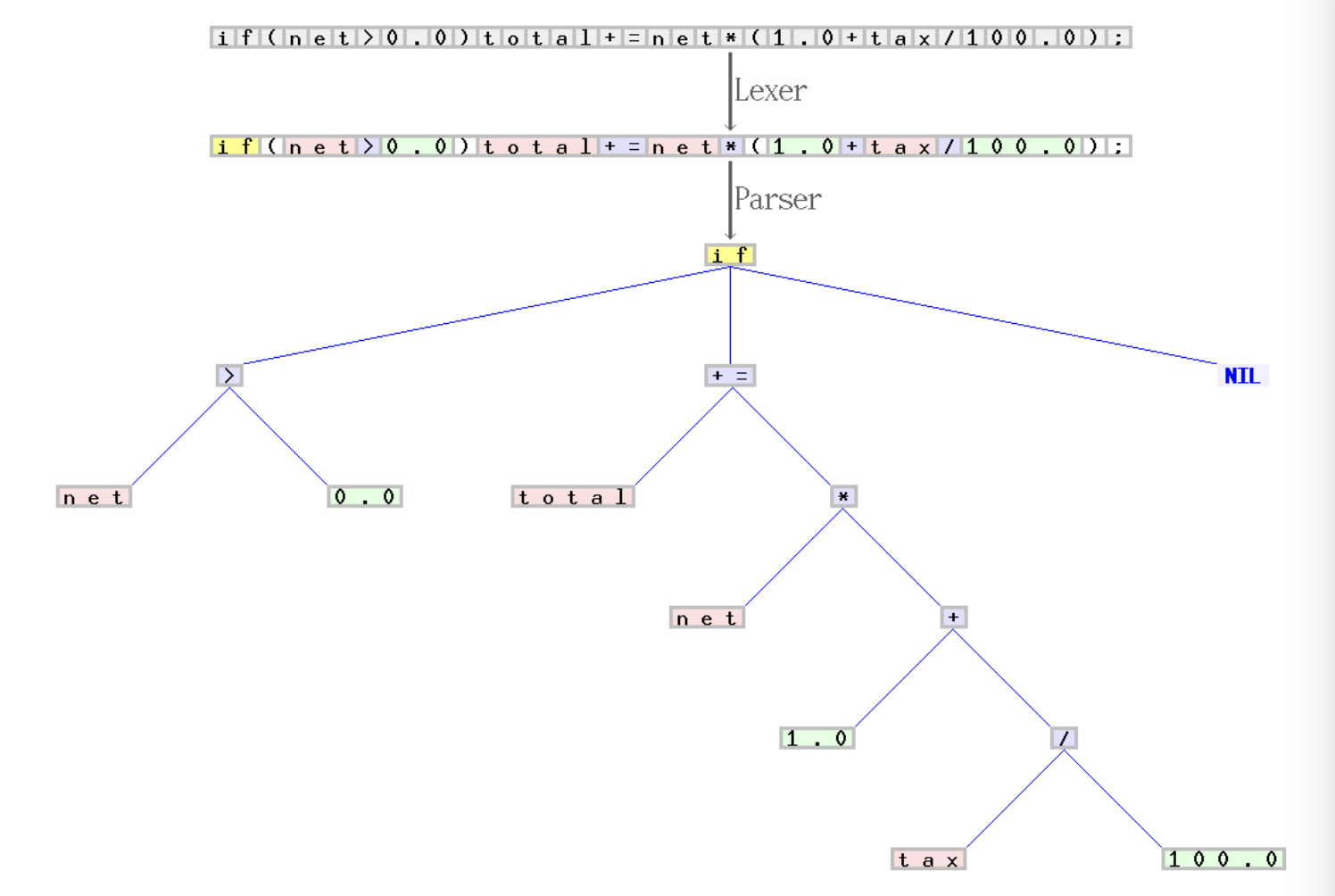
上面是 C 代码
if(net>0.0)total+=net*(1.0+tax/100.0);经过词法分析和语法分析生成的AST 结构Code generator 代码生成。
代码生成的主要任务,就是将上述的中间结果即 AST 树结构转换成一行行线性的机器指令。包括
选用什么样的指令。通过对 AST 树执行后续遍历 (postorder traversal) 依次选用指令。例如,对于 AST
W := ADD(X,MUL(Y,Z)),根是ADD,左右节点分别是X和MUL(Y,Z),指令会是t1 := X和t2 := MUL(Y,Z),最后是ADD W, t1, t2安排指令顺序。由于CPU流水线机制,可能会有乱序执行以提高代码执行效率。
变量的寄存器分配
调试代码生成
此外它还会对生成的指令进行一定的优化。
很多情况下,代码生成的机器指令为汇编代码,包含了很多汇编指令。
下面是 filename.c 编译生成的汇编指令代码 filename.s
1 | 1 .file "filename.c" |
编译过程还可以被分为 前端、后端,前端包括前面提到的词法分析、语法分析,生成 AST 结构;后端指代码生成,输入是 AST,输出机器指令代码或者汇编代码。其实,前后端中间还有个中端,做些优化的工作。
前后端的工作是独立的,互相不依赖。对于不同的语言,编译器可能使用不同类型的前端来生成 AST,而后端其输入只要求是AST,因此可以复用。举例来说,对于知名编译器 GCC (the GNU Compiler Collection),其不同的前端可以编译 C,C++,Objective-C,Fortran,Ada,Go,D 成 AST,而通过统一的后端将 AST 转换成汇编代码。
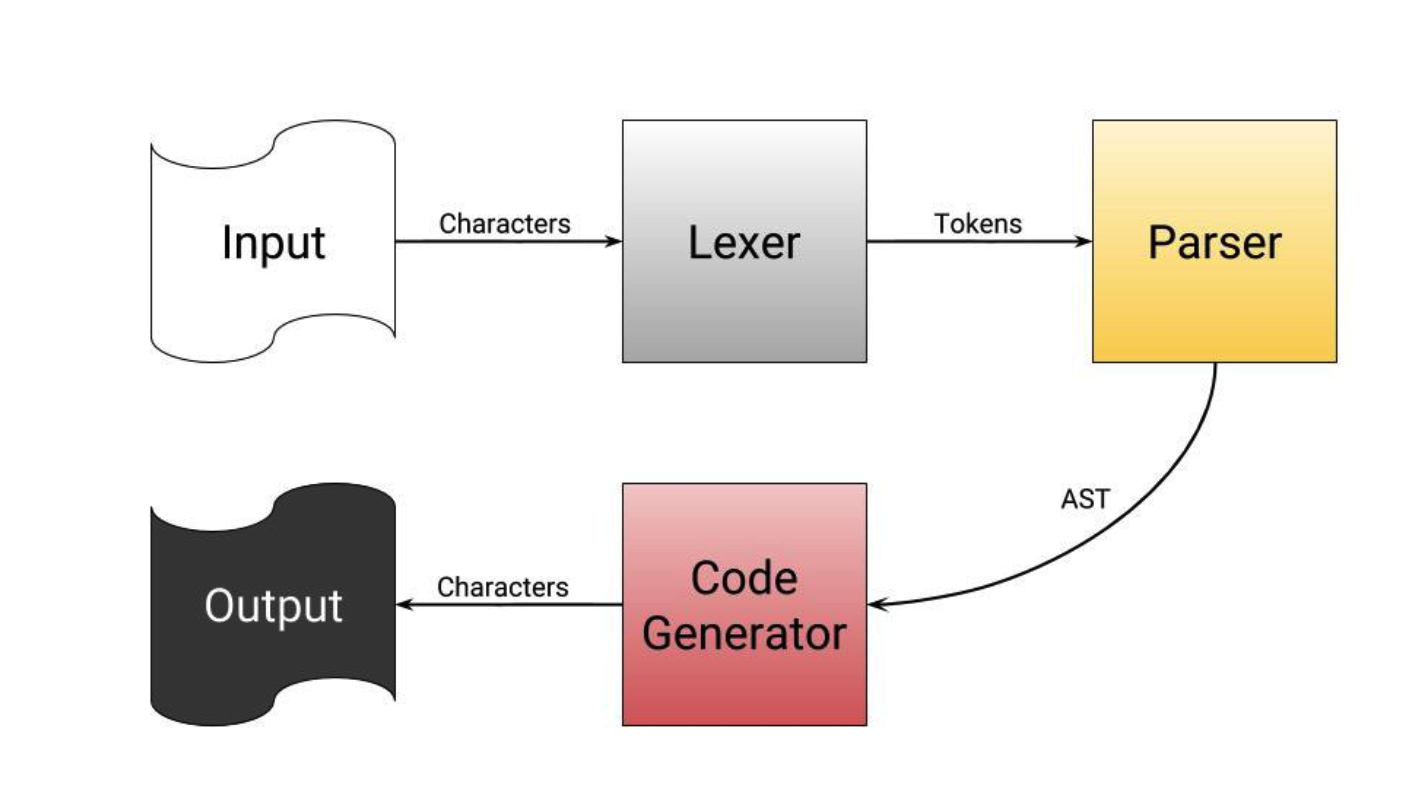
编译的整个过程用一张图来表示就是
汇编(Assembly)
该过程通过调度汇编器(as)来完成,将汇编指令文件filename.s 翻译成与处理器结构有关的机器指令文件filename.o,这是一个二进制文件,不能直接查看,用 file 命令查看可知
1 | $ file filename.o |
这一个64位 ELF 文件,可以使用 objdump -x 命令来查看所有文件头,包含符号表和重定位信息等
1 | $ objdump -x filename.o |
上面符号表里的 text 表示在代码段找到了定义,而有 UND 标识的 puts函数和printf函数因为属于库函数,尚未链接进来,因此属于未定义。
上面的filename.o 文件虽然是二进制指令文件,但是还不能被执行。最终的可执行文件还要经过下面的链接过程。
链接
该阶段由编译器驱动程序驱动链接器 linker 来完成。linker 只和平台有关,是不同操作系统下的工具程序。对于windows平台,linker.exe 是链接器 (集成在Visual Studio中),它将多个.obj文件和库文件一起链接成 .exe可执行文件或库文件;对于 linux 和 mac 平台,ld (也是GNU出品) 是链接器,它将多个 .o 文件和库文件一起链接成二进制可执行文件或库文件。
链接器的工作主要包含:地址和空间分配(Address and Storage Allocation),符号决议(Symbol Resolution),重定位(Relocation)等。
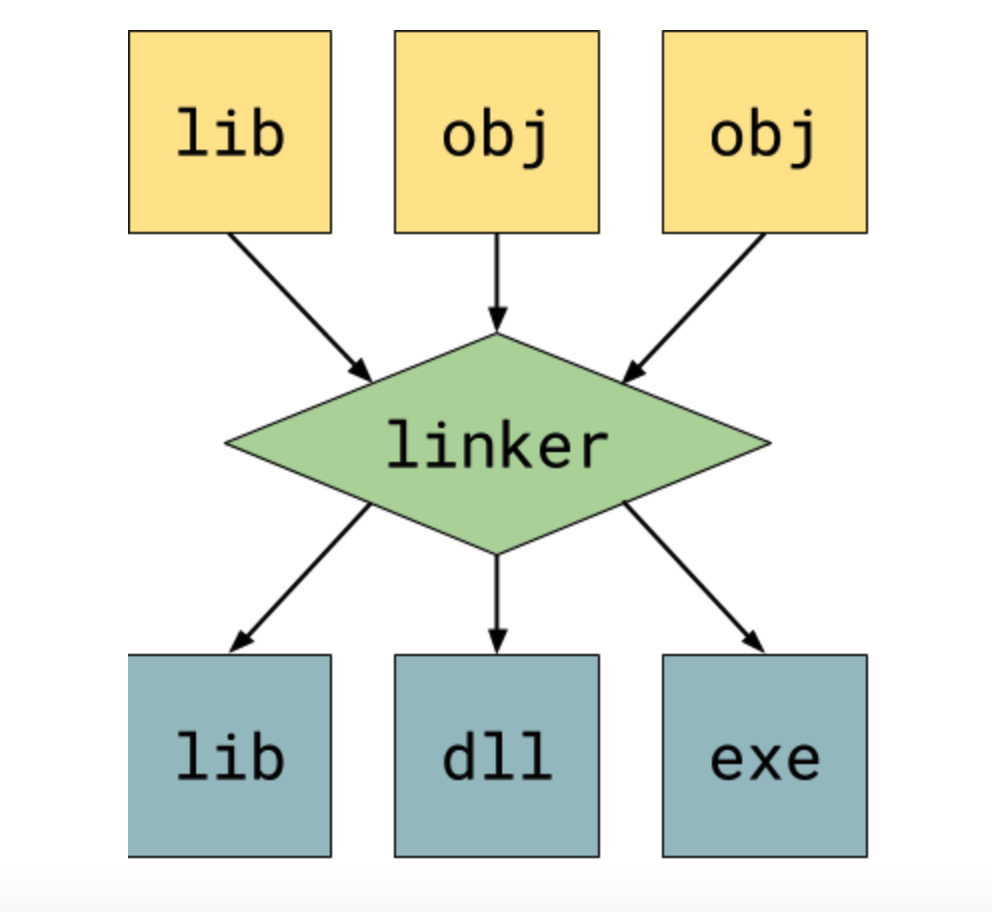
链接主要分为动态连接和静态链接。对于静态链接,linker 会将静态库的代码直接加到可执行文件中,因此文件大小比较大。而动态链接则是指链接阶段仅仅只加入一些描述信息,而程序执行时再从系统中把相应动态库加载到内存中去。
GCC 默认使用动态链接方式链接库文件。对比目标文件filename.o 和我们链接完成的可执行文件 filename大小可知,text 部分增加的大小为必要的描述信息
1 | $ size filename.o |
再看file命令的输出
1 | $ file filename |
可见与上面的filename.o不同的是该文件已经链接(GCC 默认动态连接 Linux 的 c 运行时库 libc.so.6,即 glibc )
此外,利用 ldd 命令可以看到可执行程序依赖的动态链接库
1 | $ ldd -v filename |
总结
用一个图来表示整个编译的过程如下
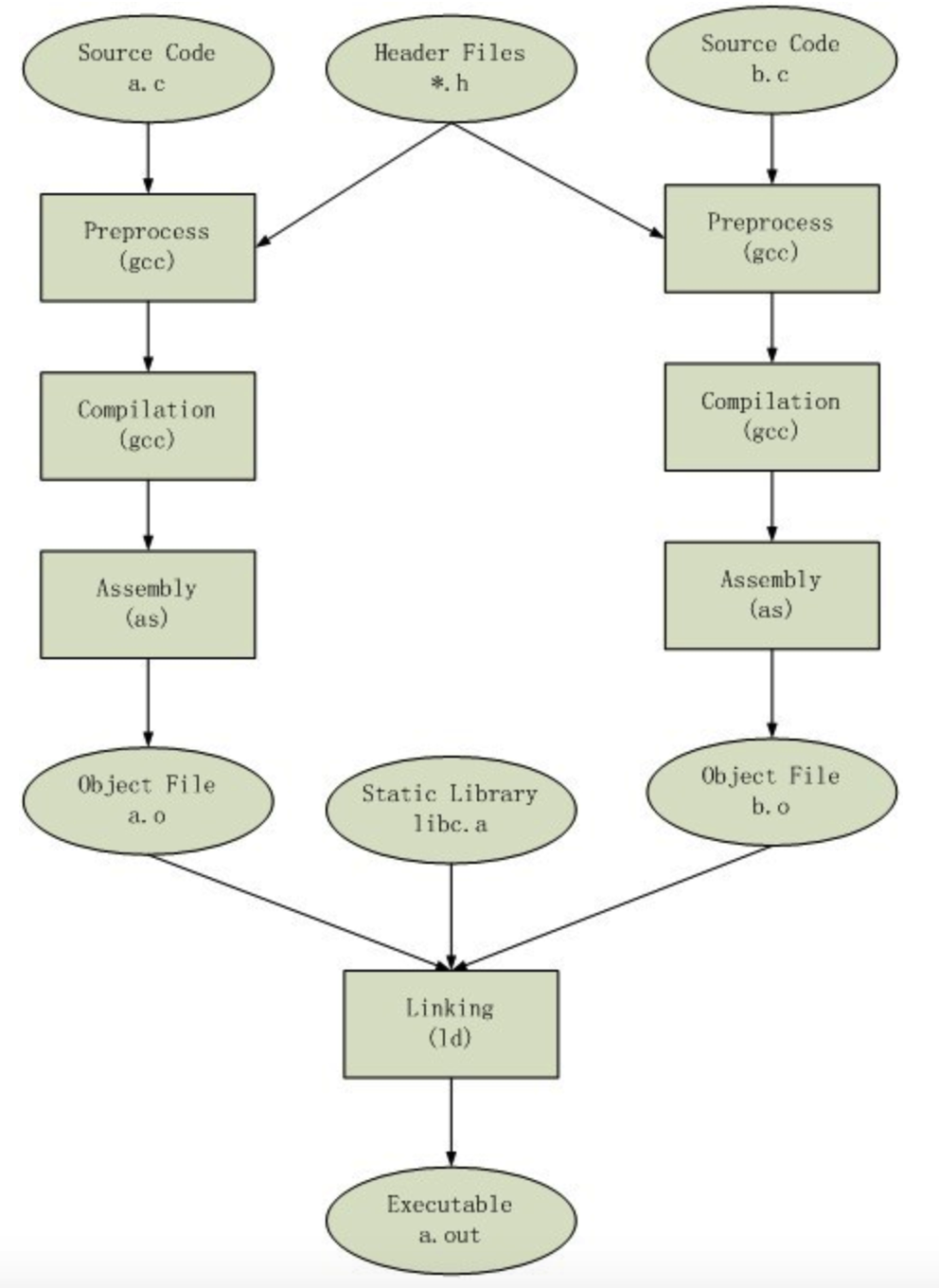
参考资料
<C专家编程>
Compiling a C program:- Behind the Scenes