Go 的 Runtime
下面这张图说明了 Go 程序在执行时与操作系统的大致交互原理。
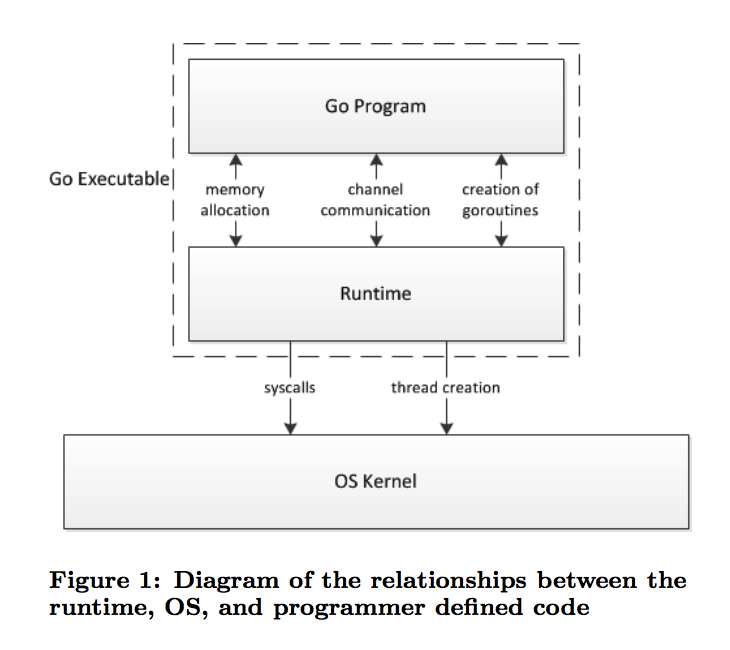
我们编写的 Go 程序除了运行自己的逻辑之外,还会涉及到与操作系统的交互,例如分配内存、创建 goroutine、通过channel与其他 goroutine 进行交互等。那么程序代码和操作系统之间是怎么交互的呢?这就用到了 go 里的 runtime 库。runtime 库主要的功能包含垃圾回收、调度、goroutine 管理等。
上图中程序代码和 runtime 库一起运行在用户空间,并在必要时(例如触发系统调用) 时与操作系统进行交互。
本文我们将只讲述 Runtime 库的调度器,其他不做涉及。
Runtime Scheduler
调度器的必要性
既然操作系统可以帮助我们来调度线程,那么为什么Go 还要实现一个用户空间级别的调度器呢?
Posix 的线程 API 本质上是对 Unix 进程模型的逻辑扩展,所以有很多类似于进程的控制机制,例如线程有自己的信号掩码,可以被指定到固定的 CPU 上执行,可以被放入 cgroups等等,这些控制机制使得线程运行时有很大的开销(overhead)。想想一下如果随着 goroutine 的增加,你的进程里有100,000个线程的情景。其实对于 goroutine,这些开销并不那么必要。
另外一个问题是垃圾回收时,调度会发生在任意时间点,需要所有线程停止执行,直到待回收的 memory 处于一致性的状态,中间只能等待。而有了 go 的调度器,它只会在线程内存处于一致性的时候进行垃圾回收,也就是说只需要等待那些正在 CPU 上运行的线程(等待他们的内存趋于一致性)。
调度模型
通常有三种线程调度模型:
- N:1模型。N 个用户级的线程运行在一个 OS 线程上。由于是多个用户级线程,因此上下文切换很快;但是不能利用到CPU 的多核特性。
- 1:1模型。本质上是 N:N 的模型,每个用户线程唯一对应了一个 OS 线程,好处是利用了所有的核心,但是线程间上下文切换非常慢,因为要跨越 OS。
- M:N 模型。这是 go使用的调度模型。它将任意多个 goroutine 运行在任意数量的 OS 线程上(通常 goroutine 数量要远多于OS线程数量),既充分利用了多核,又能很快的调度(goroutine 调度)。
调度原理
为了完成 goroutine 的调度,go 给出了三个概念M、P、G
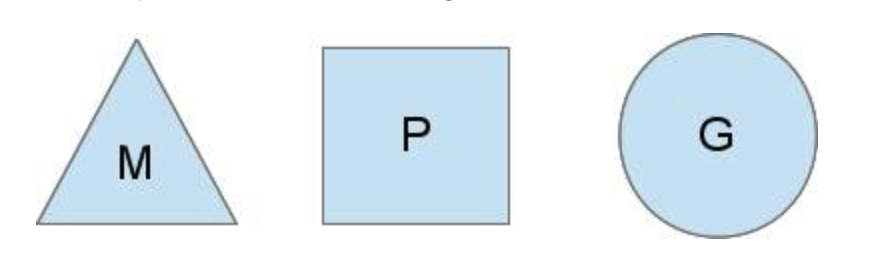
G 就是我们的 goroutine,是用户级别的调度单位。它有自己的栈、指令指针(IP)及调度器需要的信息、状态等。
M 代表 OS 线程,由操作系统负责管理。M 用来实际执行 G。
P 是一个抽象概念。在 G 被 M 实际执行前,P 负责管理多个待执行的 G。如果 M 中的 G 执行完毕,则会从 P 中 顺序取出另一个待执行的 G 来执行。
通过多个 P 可以将 N:1的调度模型转为 M:N 的模型。每个 P 对应了一个 M 来实际执行 G。
大致的调度示意图如下
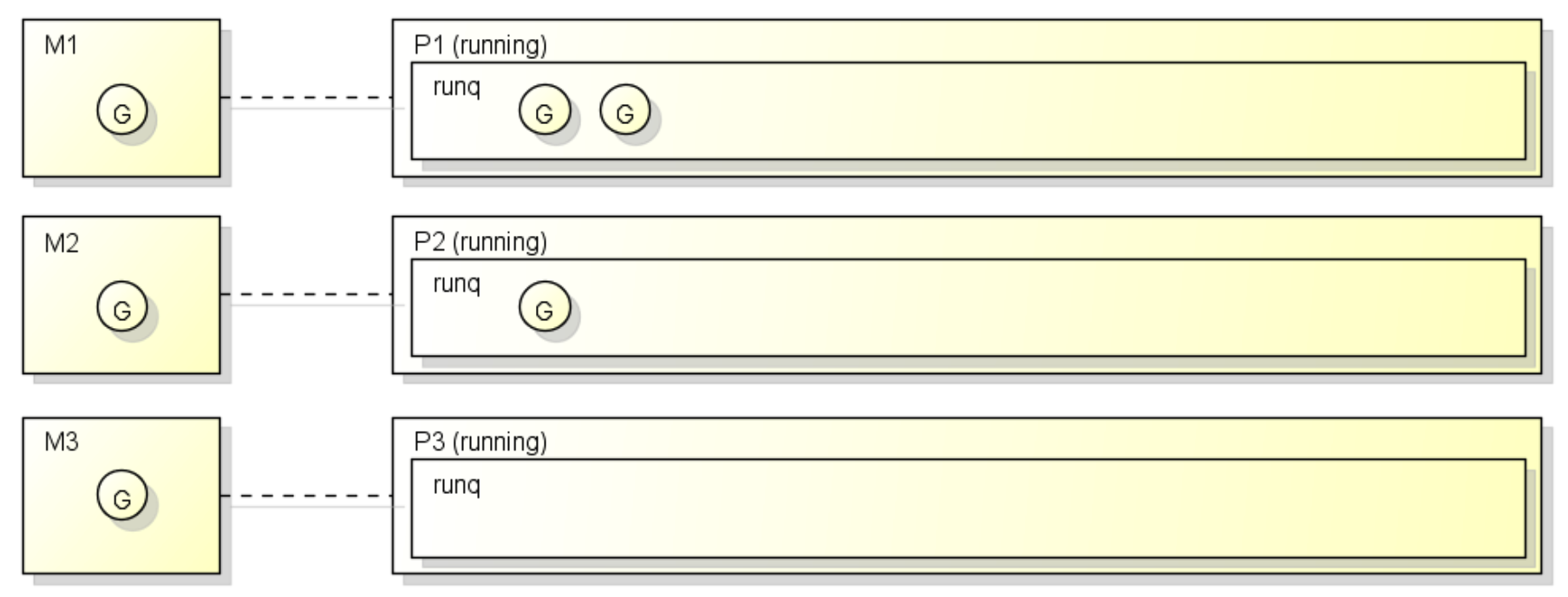
图中一共有6个 goroutine,被放入 3 个队列 P1、P2、P3 来调度。其中有 3 个 G 已经在对应的 M 中运行,另外 3 个在队列中等待执行。
那么程序启动后如何选择 P 的数量呢?默认情况下,它等于 CPU 的逻辑核心数。例如我的 Mac 是单 CPU 双核四线程的,则 P 的数量就是 4。这个数量也可以通过 GOMAXPROCS 环境变量或者 runtime.GOMAXPROCS() 函数来进行设置,一般来说使用默认的即可。
下面我们分别来看看以下几种场景,调度器如何工作:
场景1:创建 goroutine
goroutine 的创建通过 go func()语句来触发,实际调用的是 runtime.newproc 函数
1 | func newproc(siz int32, fn *funcval) { |
然后调用newproc1函数
1 | func newproc1(fn *funcval, argp *uint8, narg int32, callerpc uintptr) { |
从代码可知,新的 goroutine 会被放入到特定 P 的本地执行队列中,如果 P 的本地队列已满,则会放入一个称为『全局队列』的队列,通常全局队列很少用到,大部分操作在本地队列中。
场景2:队列调度
队列的调度循环主要是schedule函数。
M 执行 G 的时候,需要关联一个 P。当 M 执行完某个 G 时,它会从 P 的等待队列中 pop 出一个新的 G 来执行。注意 P 的待执行本地队列是一个无锁队列,存取都是比较高效。而全局队列会被很多 P 访问,因此加入了锁保证安全性。选择可以执行的 G 通过函数findrunnable()来完成。
1 | // Finds a runnable goroutine to execute. |
在findrunnable()中,并不总是从本地队列里取,否则全局队列里的 G 将被『饿死』,永远无法执行。为了公平起见,每61次调度检查一下全局队列。此外, go 的网络操作也是整合到 runtime 中的,findrunnable 也会从 network 从寻找阻塞的 G 来执行。
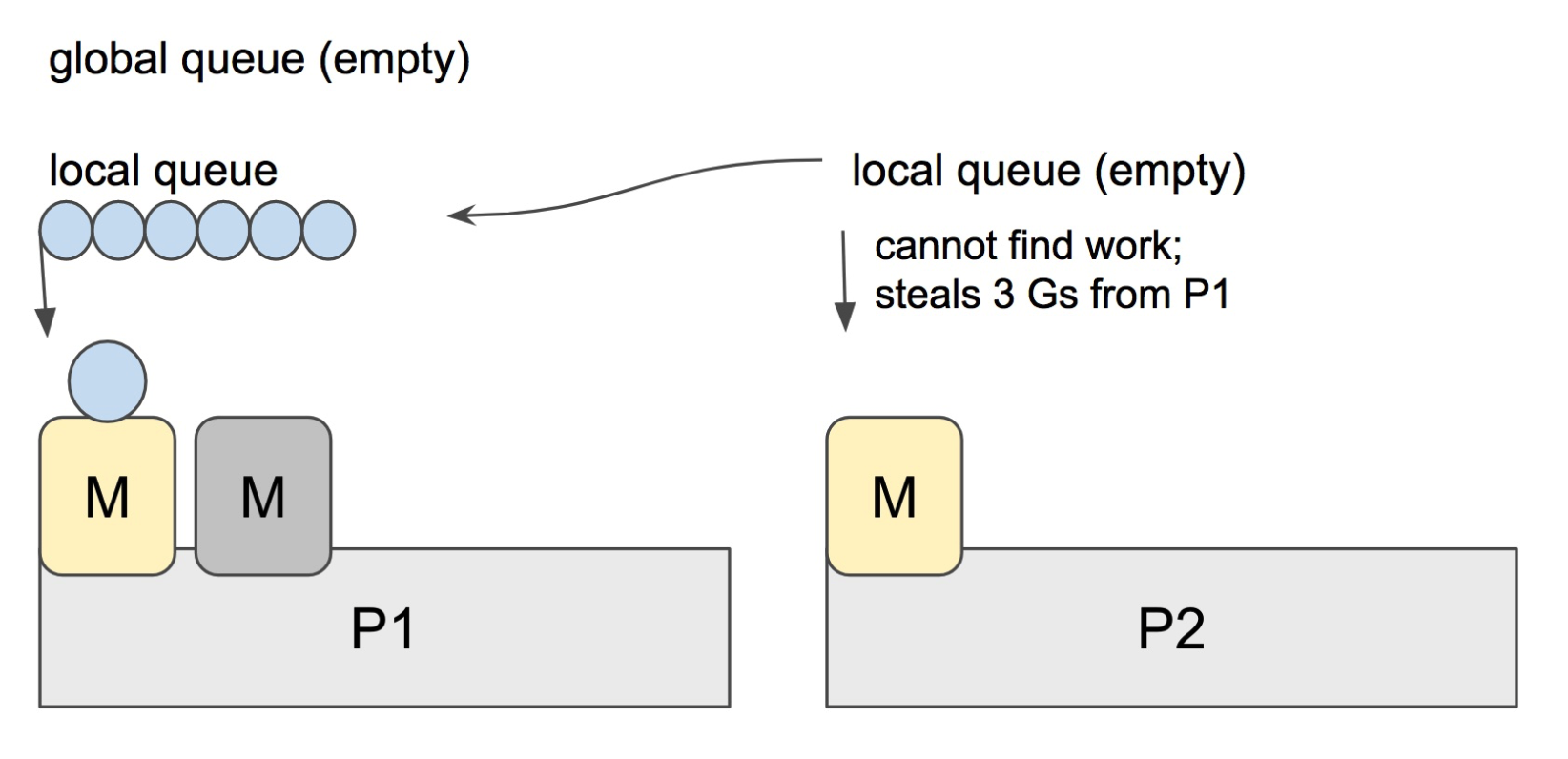
如果以上所有都没有可供执行的 G 呢?我们不能让该工作线程 M 处于空闲状态,必须充分利用。为此,就用到了一种被称为Work-Stealing 的调度算法,当前 P 会尝试从其他的 P 随机选择一个,从中『偷取』一半的 G 放入本队列,于是当前 P 又可以继续调度了。Work-Stealing 保证了整个调度系统内队列的平衡。示意图如下
场景3:执行中断
我们知道,当一个 G 在 M 中执行时,队列中的其他 G 会处于等待状态,那么如果这个 G 中的代码是个长时间执行的代码,那其他 G 会一直等待,直到 G 执行完成吗?我们通过一段代码来看看。简单起见,我们设置 P 的数量为1。
1 | package main |
执行结果如下:
1 | $ ./runtime2 |
可见,前一个 goroutine 执行完成之后才会执行下一个 goroutine。
这里注意,goroutine 的执行顺序和代码里的顺序正好相反,是因为最新创建的 goroutine 被放入了优先执行队列 runnext 里。所以后创建的 goroutine 反而最优先执行。
有没有可能是前一个 G 执行太快导致后一个G 没来得及执行?为此我们将后一个 goroutine 改为死循环
1 | package main |
执行结果显示,打印数字的 goroutine 永远得不到执行。
那 goroutine 可能被中断执行吗?答案是 yes。正在运行的 goroutine 中如果有以下操作,将会导致其被中断执行
- 系统调用 (例如打开一个文件)
- time.Sleep
- channel 读写操作
- sync 包中的锁操作
- 网络 IO
- 主动调用 runtime.Sched()
中断执行的 M 及其 G,会从对应的 P 上 detach,进入阻塞状态,等待系统调用或者其他操作的完成。而 P 会尝试寻找另一个可用的 M,使其可以继续调度后续的 G 来执行。一般可以从空闲的 M 中选择一个,如果没有空闲的 M,则新创建一个 M(OS 线程)来 attach 到 P 上,如下图所示
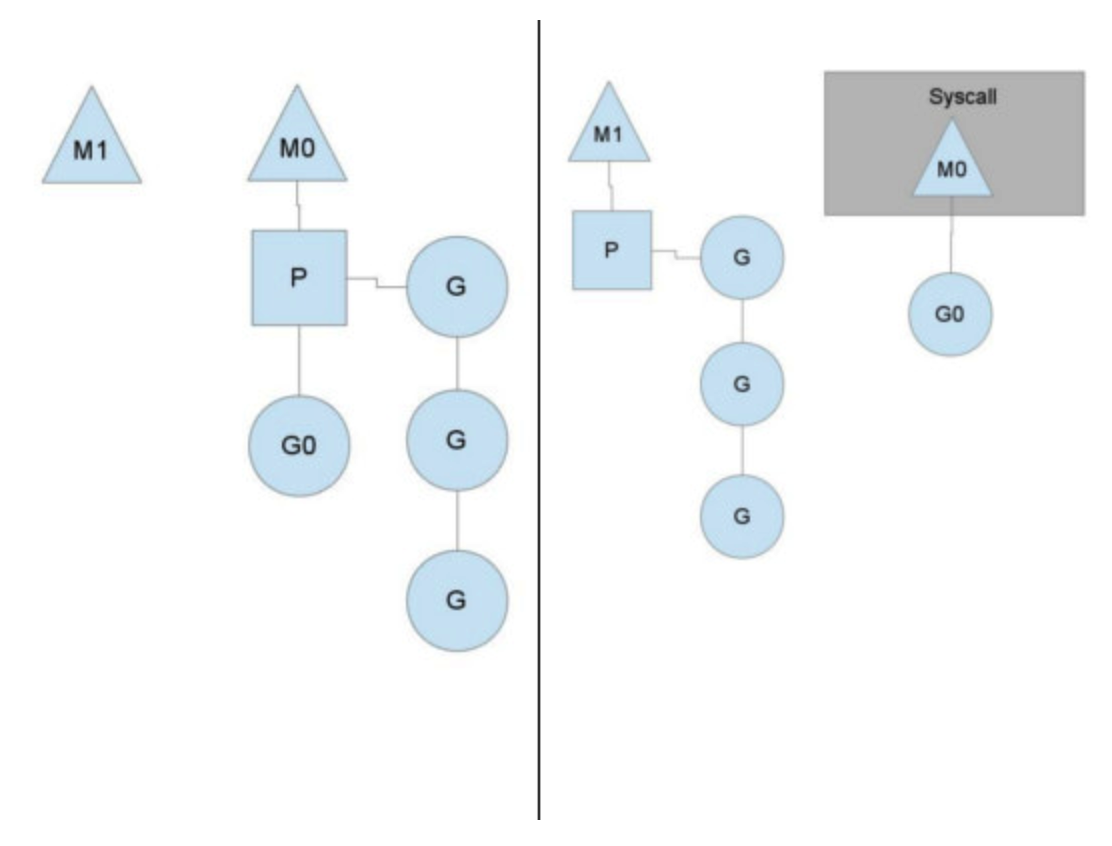
我们看到
- 线程 M0 放弃了它关联的 P,开始等待阻塞的 OS 调用的完成;
- P 找到了一个线程 M1(空闲的或者新建的) 继续调度;
- 当 M0上的 OS 调用完成后,它需要找到一个可用的 P 来继续执行返回的 G 上的代码
- 如果没有找到可用的 P,则 M0 会将其上的 G 放到全局队列,自身进入空闲状态,被动等待其他 P 调用
这里我们利用一段代码来实验下这个特性。现在在死循环过程中周期性的插入系统调用代码。常用的 fmt.Printf 打印信息到标准输出,就包含一个典型的系统调用 syscall.Write (syscall 包里还有很多其他系统调用)
1 | package main |
执行结果如下
1 | $ ./runtime6 |
显然另一个 goroutine 也得到了调度运行。
而如果 G 被阻塞在某个 channel 操作或 network I/O 操作上时,G 会被放置到一个 wait 队列中,这个队列会是 channel 的发送或接收队列或者网络 IO 的等待队列;而 M 会尝试运行下一个 runnable 的 G;如果此时没有 runnable 的 G 供 M 运行,那么 M 将解绑 P,并进入 sleep 状态。当 I/O available 或 channel 操作完成,在 wait 队列中的 G 会被唤醒,标记为runnable,放入到某P的队列中,绑定一个 M 继续执行。
这里我们使用 http 包来拉取百度首页为例来测试网络 IO 的情况
1 | package main |
执行结果如下
1 | $ go run runtime6.go |
可见网络 IO 确实触发了 goroutine 的执行中断。
综上可以知道:
即使设置 GOMAXPROCS 为1,程序仍然可能会执行在多个OS线程上,即实际上的并发执行(非并行执行)
抢占调度
G-P-M模型的实现算是Go scheduler的一大进步,但Scheduler仍然有一个头疼的问题,那就是不支持抢占式调度,导致一旦某个G中出现死循环或永久循环的代码逻辑,也没有导致中断执行的调用,那么G将永久占用分配给它的P和M,位于同一个P中的其他G将得不到调度,出现『饿死』的情况。更为严重的是,当只有一个P时(GOMAXPROCS=1)时,整个Go程序中的其他G都将“饿死”。于是Dmitry Vyukov又提出了《Go Preemptive Scheduler Design》并在Go 1.2中实现了『抢占式』调度。
这个抢占式调度的原理则是在每个函数或方法的入口,加上一段额外的代码 (morestack调用),让runtime有机会检查是否需要执行抢占调度。这种解决方案只能说局部解决了“饿死”问题,对于没有函数调用,纯算法循环计算的G,scheduler依然无法抢占。为此,我们利用下面这段代码看看抢占式的调用是否起效
1 | package main |
这段程序是对前面一段死循环赋值程序的改写,使用了函数调用。需要注意的是,在编译时候需要禁用编译器优化,否则简单函数将被内联优化掉
1 | $ go build -gcflags="-N -l" runtime5.go |
另外,为什么不直接调用 myfn 函数,而是中间再插入一个dummy函数呢?那是因为 myfn 函数位于调用树的leaf(叶子)位置,compiler可以确保其不再有新栈帧生成,不会导致栈分裂或超出现有栈边界,于是就不再插入morestack 来检查是否需要进行抢占式调度。具体实验过程可以参考 TonyBai 的 这篇文章
调度追踪
golang 的 runtime 库提供了 GODEBUG 来输出调试信息,通过 schedtrace=X 选项可以使调度器每隔一定时间向标准错误输出调度状态。我们利用该选项追踪一下下面这段代码的调度过程
1 | package main |
使用 GODEBUG 来观察调度器的执行情况 (使用默认的 GOMAXPROCS = 4)
1 | $ GODEBUG=schedtrace=1000 ./runtime4 |
首先看下 1000ms
1 | SCHED 1000ms: gomaxprocs=4 idleprocs=4 threads=6 spinningthreads=0 idlethreads=4 runqueue=0 [0 0 0 0] |
此时,4个工作线程 M 刚刚被创建,对应 4 个 P,并处于 idle 状态;另有 2 个线程被 runtime 使用,一共是 6 个线程
1 | SCHED 2006ms: gomaxprocs=4 idleprocs=0 threads=6 spinningthreads=0 idlethreads=1 runqueue=0 [2 1 2 1] |
在 2006ms,idleprocs 为 0,表示 4 个 procs 均处于工作状态,各持有一个 G,剩余的 6 个 G 分别放置在4个 P 对应的本地队列中 ( 2 + 1 + 2 + 1),全局队列中有 0 个 G
1 | SCHED 7035ms: gomaxprocs=4 idleprocs=0 threads=6 spinningthreads=0 idlethreads=1 runqueue=3 [2 0 1 0] |
在 7035ms,有 3 个 G 执行完成,放入全局队列中等待结束,再从 3 个 P 中取出 3 个 G 放入 M 中执行,因此全局队列和本地队列数量分别是 runqueue=3 [2 0 1 0]
1 | SCHED 8041ms: gomaxprocs=4 idleprocs=0 threads=6 spinningthreads=0 idlethreads=1 runqueue=4 [1 0 1 0] |
在 8041ms,又有一个 G 执行完成,放入全局队列中,再从其关联的 P 中取出一个 G 放入 M 中执行,因此全局队列和本地队列数量分别是 runqueue=4 [1 0 1 0]
1 | SCHED 13064ms: gomaxprocs=4 idleprocs=0 threads=6 spinningthreads=0 idlethreads=1 runqueue=0 [0 0 0 0] |
在 13064ms,此时没有待执行的 G 了,只有 4 个正在执行的 G,其余 6 个都已经执行完毕并退出
1 | SCHED 17087ms: gomaxprocs=4 idleprocs=4 threads=6 spinningthreads=0 idlethreads=4 runqueue=0 [0 0 0 0] |
在17087ms,所有 G 执行完毕,idleprocs=4,所有 proc 处于空闲状态
更详细的关于追踪的情况,可以参考 William Kennedy 写的博客 [ Scheduler Tracing In Go]https://www.ardanlabs.com/blog/2015/02/scheduler-tracing-in-go.html
参考资料