引子
无锁队列是一种广泛使用的数据结构
单读单写
我们先看下最简单的一种情况,就是一个生产者负责写,一个消费者负责读的情况。
这种情况通常是利用环形缓冲区 RingBuffer (有时候也称为 circular queue)来实现,那首先看看 RingBuffer 是怎么实现读写的。
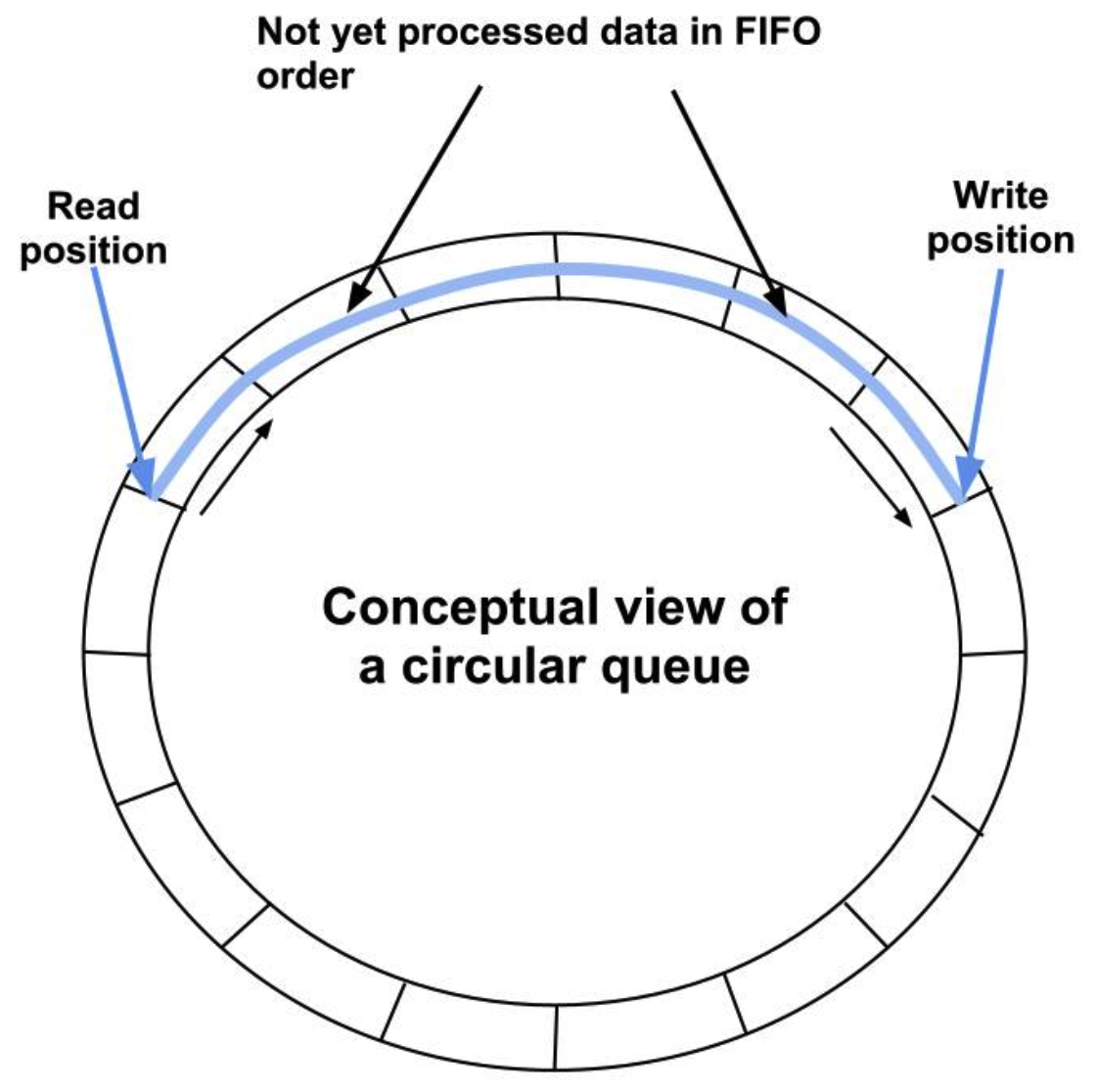
RingBuffer 实现
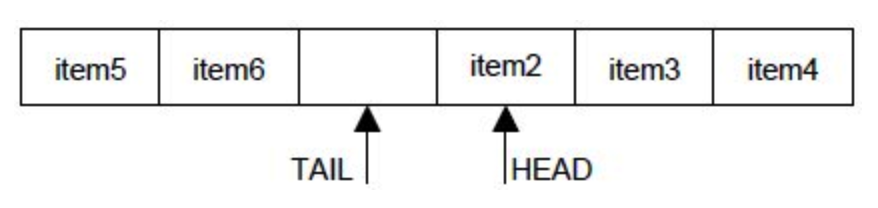
一个数组buff,大小是 SIZE,两个指针变量 head 和 tail 来表示队列的头和尾。写的时候,控制 tail 加1;读的时候,控制 head 加1。
- 初始状态,数组为空,tail 和 head 都为 0
- 写入元素时,tail 加1向后更新
- 读取元素时,head 加1向后更新
- 由于数组大小size有限,tail 或者 head指针不能永远向后增加,当到达数组尾部(指向
size-1)的时候,需要绕回到数组开头,实现的时候使用val = (val + 1) % size取余即可 - 绕回的机制正是环形缓冲的特色,因此 head 和 tail 的前后关系可能会一直变化
- 队列为空时,读取失败,此时 head 和 tail 相等
- 队列满时,写入失败,规定如果 tail + 1后,做可能的回绕,然后检查 tail 和head 是否相等,如果相等则满。这种约定浪费了一个元素的位置不让写入,从而保证写满时,head 和 tail差一个元素而不是相等,和队列为空的情况区分开来。此时的情况是可能是
- tail 在前,head 在后且为 0, tail - head = size - 1 ,此时队列里除最后一个元素外全满,tail + 1 回绕后和head 都为 0
- head 在前,tail 在后,且 head - tail = 1,tail 加1后和 head 相等
PUSH
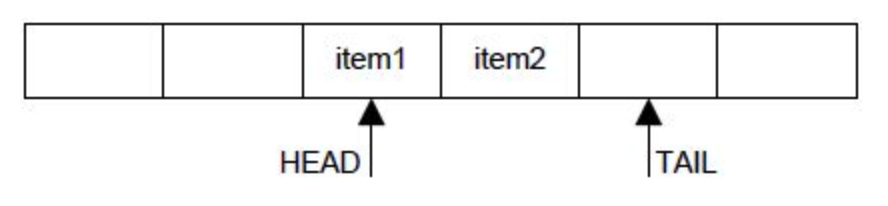
POP
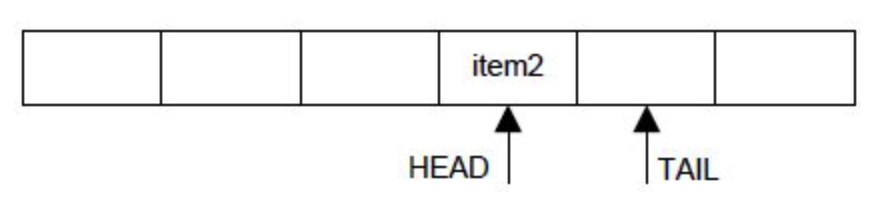
EMPTY
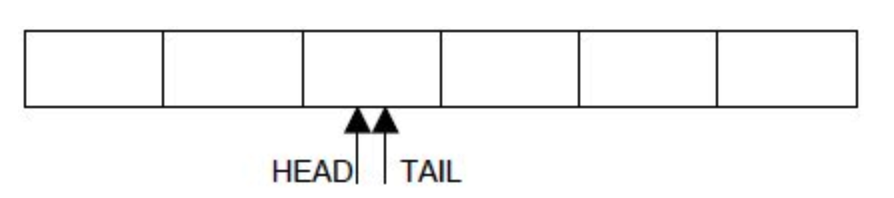
FULL
下面看下实现代码
1 |
|
原子性
现在回到初始的单读单写的情况,生产者调用 push() 来唯一控制 tail 的更新,而消费者调用 pop() 来唯一控制 head 的更新。
实际实现时,通常分步,写入(或读取)缓冲区内容,更新指针。我们要保证:
- 对 tail 和 head 指针的更新必须是原子的
- 读的时候,先读取缓冲区内容,再更新 head
- 写的时候,先写入内容到缓冲区,再更新 tail
关于 int 类型赋值的原子性,C++ 标准是没有定义的,依赖于编译器的实现和系统架构的内存对齐策略等。
根据 KjellKod.cc 的文章的说法,大部分现代处理器上,对于自然对齐的基础类型的读写是原子的,不会出现读一半或者写一半的情况。对于 x86 和 x64 平台,长度大于8的类型,其读写不保证是原子的。而对于我们的 head 和 tail,在 32 位处理器和 64 位处理器上大小分别是 4 和 8 (注:int 的大小和平台和编译器实现有关,这里说法不准) ,因此可以保证是原子的。其英文原话是
1 | On almost all modern processors, reads and writes of naturally aligned native types are atomic. This means that as long as the memory bus is at least as wide as the type being read or written the CPU reads and writes will happen in a single bus transaction. This makes it impossible for other threads to see them half-completed. |
保险的措施是使用c++11中的 std::atomic 来保证原子性。我们修改下 head 和 tail 定义后的 ssqueue 结构(single producer & single consumer queue) 如下
1 |
|
顺序执行
由于都是分步执行,中间有可能被打断。但是只要保证了读写缓冲区的和更新指针的顺序,就能保证无锁的安全性。
现在来分析一下打断的情况:
假如读的时候,消费者先读取了缓冲区内容,而未来得及更新 head,执行权就被生产者抢占,于是生产者读的 head 就是老的,类似快照数据。但这并没有太大影响,顶多是极端情况下由于没有更新head 导致生产者认为队列满而写入失败,下次继续写就可以了;如果队列没满,写入不受影响。
同样的道理,假如写的时候,生产者先写入内容到缓冲区(也可能是写一部分),而未来得及更新 tail,执行权就被消费者抢占,于是消费者读到的 tail 也是老的。这也没有多大影响,顶多是极端情况下由于没有更新tail导致消费者认为队列空而读取失败,下次继续读就读到数据了;如果队列非空,读取不受影响。
这里特别注意的是,head 和 tail 指针永远只由一方来更新,且是单方向更新。
那是不是代码里先写缓冲区操作,再写更新指针操作就可以了呢?答案是否。
编译器优化我们的代码时,可能会改变代码的执行顺序,反应在汇编指令的前后顺序调整。这是编译时乱序。
上面提到的利用 volatile 修饰的 int 变量,vs 和 gcc 编译器似乎都能保证其汇编指令顺序,但是没有得到权威的资料证明 (查看)
此外,由于现代CPU普遍采用了多级流水线技术,一条指令的执行是多级流水线协同完成。为了提高执行效率,可以同时执行多条指令;而且随着分支预测和乱序执行的引入,互不依赖的两条指令在执行时是不保证先后顺序的,这是运行时乱序。
编译器开发者和cpu厂商都遵守着内存乱序的基本原则,简单归纳如下:
1 | 不能改变单线程程序的行为 |
在单线程环境,我们不必关心内存乱序的影响。而此时,我们关注的恰恰是多线程执行的情况,如何保证我们代码的顺序执行就是需要解决的关键问题。
一种方式是依赖 volatile int 的一种实现。
1 | volatile int head; |
这里特别指出,volatile 关键字语义上只是提示编译器不要优化该变量,本质上和顺序执行没有任何关系。有说法是 volatile 的使用保证读写变量时其汇编指令顺序不会变更,但是没有可靠依据。
而对于执行乱序
1 | CPU Reordering Summary for x86 and x64 Platforms |
由 2、3 两条保证了写的顺序不被置于读之前,且写之间顺序不乱。
同样,保险的方式还是使用平台无关的机制:c++11提供的内存屏障。
Acquire-Release 内存屏障代码
1 |
|
http://chonghw.github.io/blog/2016/09/05/compilermemoryreorder/
多读多写
如果情况扩展到多读多写的情况,我们就不能像上面这样来实现了。必须要借助 CPU 提供的 CAS 操作指令。
CAS
Compare & Set,或是 Compare & Swap,现在几乎所有的CPU指令都支持CAS的原子操作,X86下对应的是 CMPXCHG 汇编指令。有了这个原子操作,我们就可以用其来实现各种无锁(lock free)的数据结构。
维基百科是这么说的
1 | In computer science, compare-and-swap (CAS) is an atomic instruction used in multithreading to achieve synchronization. It compares the contents of a memory location with a given value and, only if they are the same, modifies the contents of that memory location to a new given value. This is done as a single atomic operation. The atomicity guarantees that the new value is calculated based on up-to-date information; if the value had been updated by another thread in the meantime, the write would fail. The result of the operation must indicate whether it performed the substitution; this can be done either with a simple boolean response (this variant is often called compare-and-set), or by returning the value read from the memory location (not the value written to it). |
使用 c 代码形象的来表示这个操作就是
1 | bool compare_and_swap(int *accum, int *dest, int newval) |
将变量值 accum 与 dest 进行 compare,如果相等则进行 Swap/Set。如果不相等,则返回一个标识值。上层需要重复调用该 CAS 操作,直到操作成功。
C 中使用 CAS
C 语言中使用 CAS,可以使用
C11)
<stdatomic.h>里的一系列函数1
2
3
4_Bool atomic_compare_exchange_strong( volatile A* obj,
C* expected, C desired );
_Bool atomic_compare_exchange_weak( volatile A *obj,
C* expected, C desired );特定编译器的非标准 C 扩展
1
2
3
4
5
6
7
8//GCC
bool __sync_bool_compare_and_swap (type *ptr, type oldval type newval, ...)
type __sync_val_compare_and_swap (type *ptr, type oldval type newval, ...)
//Windows API
InterlockedCompareExchange ( __inout LONG volatile *Target,
__in LONG Exchange,
__in LONG Comperand);直接调用
compare-and-swap汇编指令编写的函数。
下面是使用链表实现的基于 CAS 操作的无锁队列
1 | EnQueue(x) //进队列 |
ABA 问题
所谓ABA(见维基百科的ABA词条),问题基本是这个样子:
- 进程P1在共享变量中读到值为A
- P1被抢占了,进程P2执行
- P2把共享变量里的值从A改成了B,再改回到A,此时被P1抢占。
- P1回来看到共享变量里的值没有被改变,于是继续执行。
虽然P1以为变量值没有改变,继续执行了,但是这个会引发一些潜在的问题。ABA问题最容易发生在lock free 的算法中的,CAS首当其冲,因为CAS判断的是指针的地址。如果这个地址被重用了呢,问题就很大了。(地址被重用是很经常发生的,一个内存分配后释放了,再分配,很有可能还是原来的地址)
比如上述的DeQueue()函数,因为我们要让head和tail分开,所以我们引入了一个dummy指针给head,当我们做CAS的之前,如果head的那块内存被DeQueue() 然后回收并被重用了,而重用的内存又被EnQueue()进来了,这会有很大的问题。(内存管理中重用内存基本上是一种很常见的行为)
维基百科上给了一个解——使用double-CAS(双保险的CAS),例如,在32位系统上,我们要检查64位的内容
1)一次用CAS检查双倍长度的值,前半部是指针,后半部分是一个计数器。
2)只有这两个都一样,才算通过检查。然后把指针赋新的值,并把计数器累加1。
总结
无锁队列主要是通过CAS、FAA这些原子操作,和Retry-Loop实现。
对于Retry-Loop,其实和锁什么什么两样。只是这种“锁”的粒度变小了,主要是“锁”HEAD和TAIL这两个关键资源。而不是整个数据结构。
参考资料
Lock-Free Single Producer - Single Consumer Circular Queue 1
Lock-Free Single-Producer - Single Consumer Circular Queue 2
Why do we use volatile keyword in C++?